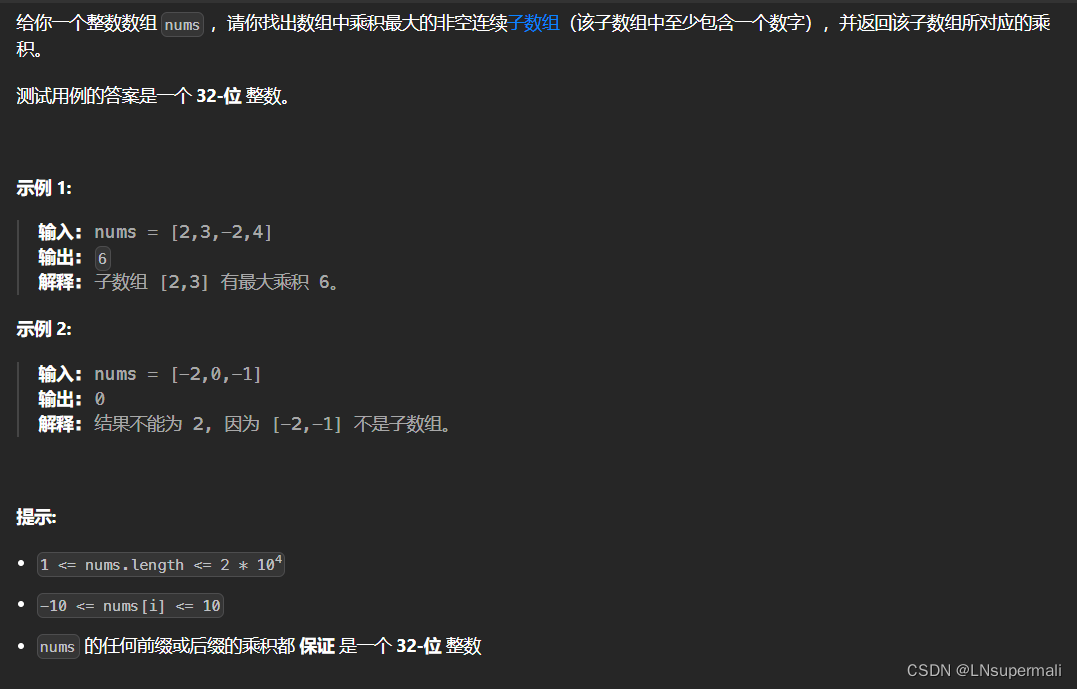
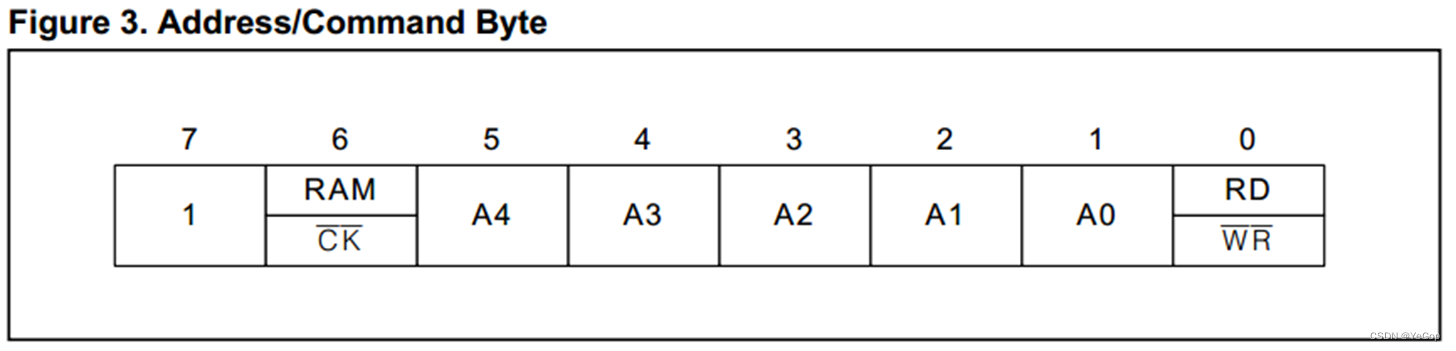
注意:本文提供下载的教程,与以下文章的思路有相同点,也有不同点,最终目标只是让读者从多维度去熟练掌握本知识点。
在Python中进行机器学习项目开发实战,预测建模是一个常见的应用场景。以下是一个简化的步骤指南,帮助你从头开始构建一个预测模型项目:
1. 确定项目目标和问题类型
- 回归问题:预测一个连续值(如房价、股票价格等)。
- 分类问题:预测一个离散值(如猫或狗、垃圾邮件或正常邮件等)。
- 聚类问题:将相似的数据点分组。
2. 收集数据
- 使用公开数据集(如Kaggle、UCI机器学习库等)。
- 从API或数据库获取数据。
- 自行收集数据(如问卷调查、爬虫等)。
3. 数据预处理
- 数据清洗:处理缺失值、重复值、异常值等。
- 特征工程:创建新特征、选择重要特征、转换特征(如编码分类变量、标准化或归一化数值特征)。
- 数据划分:将数据集划分为训练集、验证集和测试集。
4. 选择机器学习算法
- 根据问题类型选择合适的算法(如线性回归、逻辑回归、决策树、随机森林、支持向量机、神经网络等)。
- 考虑使用集成方法(如bagging、boosting)来提高性能。
5. 模型训练与评估
- 使用训练集训练模型。
- 使用验证集调整模型参数(如超参数优化)。
- 使用测试集评估模型性能(如准确率、召回率、F1分数、AUC-ROC等)。
6. 模型优化
- 特征选择:使用特征选择算法减少特征数量,提高模型性能。
- 超参数优化:使用网格搜索、随机搜索或贝叶斯优化等方法调整模型超参数。
- 集成方法:结合多个模型的预测结果来提高整体性能。
7. 模型部署与监控
- 将模型部署到生产环境(如API、Web应用、移动应用等)。
- 监控模型性能,定期重新训练和更新模型以适应数据变化。
8. 项目文档与报告
- 编写项目文档,记录数据处理、模型选择、训练和评估的整个过程。
- 准备报告或演示文稿,向利益相关者展示项目成果。
工具与库
- Python:主要编程语言。
- Pandas:数据处理和分析。
- NumPy:数值计算。
- Scikit-learn:机器学习算法库。
- TensorFlow 或 PyTorch:深度学习框架(如果需要)。
- Matplotlib 和 Seaborn:数据可视化。
实战建议
- 从简单的项目开始,逐步增加复杂性。
- 查阅相关文献和教程,了解最佳实践。
- 参与在线竞赛或项目,与同行交流学习。
- 持续关注新技术和方法,保持学习热情。